
VISOR Turns Visual RAG into an Agentic Workflow
I’m sharing this because a major new approach to visual RAG (Retrieval-Augmented Generation) just surfaced, and it could reshape how complex visual tasks are automated in enterprise AI systems. VISOR reframes how AI systems search and reason across visual corpora to solve long-horizon problems in ways traditional retrieval-augmented generation hasn’t tackled before.
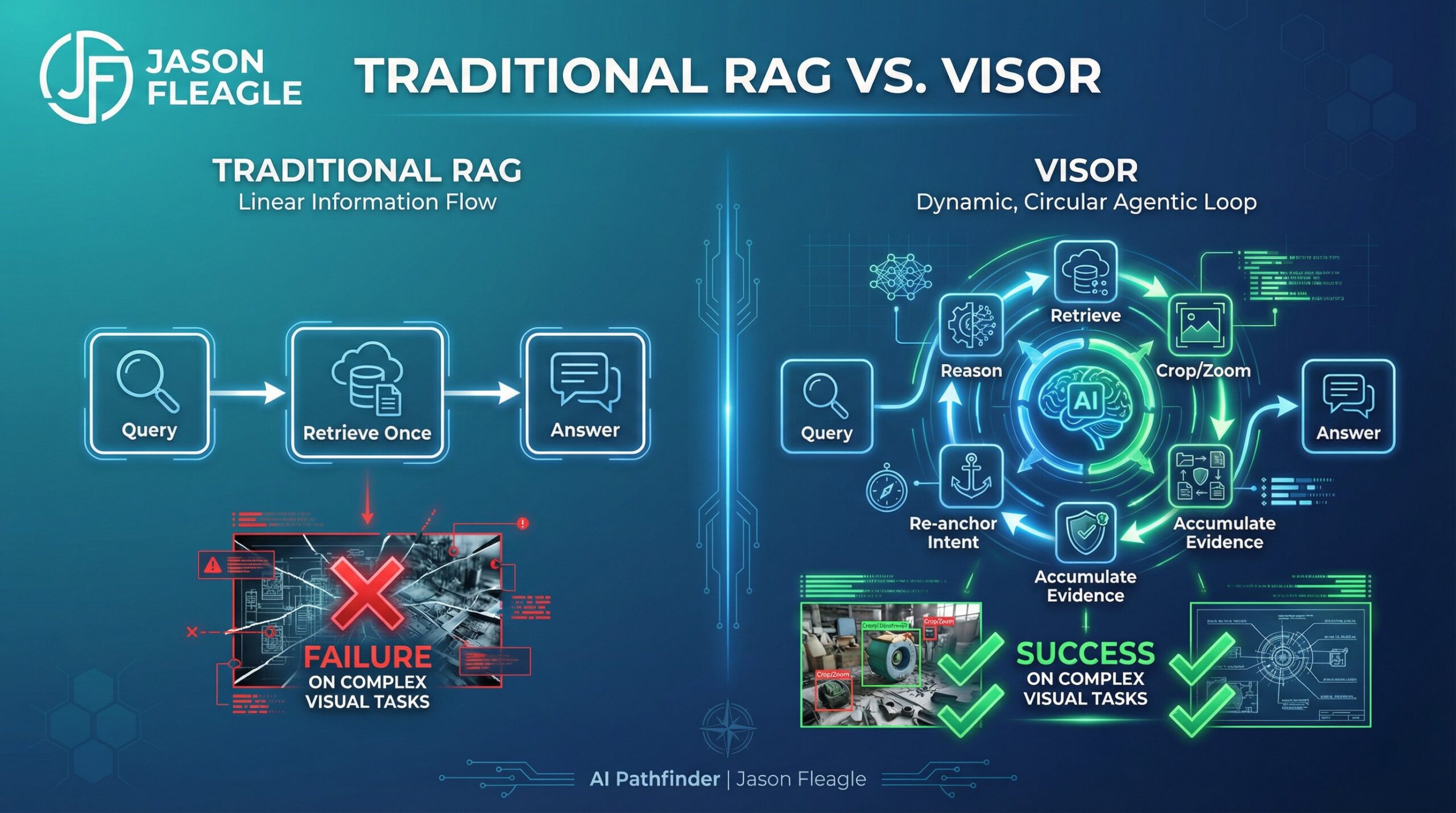
Traditional RAG has a blind spot: it retrieves once, reads, and stops. That works fine for simple text lookups. But when you’re dealing with complex visual tasks—like scanning through a 50-page slide deck to find a specific chart, zooming in on a data point, and then cross-referencing it with a table on another page—a single retrieval pass fails. This is exactly the kind of failure I covered in Why Most AI Pilots Die: systems that look capable in demos but collapse on real-world complexity.
Enter VISOR (Visual Retrieval-Augmented Generation via Iterative Search and Over-horizon Reasoning). It transforms visual RAG from a static lookup into a dynamic, agentic workflow that keeps thinking across multiple steps without losing the plot.
What Is VISOR and How Does the Agentic Visual RAG Loop Work?
VISOR is an agentic loop that interleaves reasoning with iterative visual retrievals to gather evidence scattered across images or pages. It’s built specifically for tasks that can’t be solved with a single lookup—the kind of multi-step reasoning that makes AI actually accurate rather than confidently wrong.
Unlike standard visual RAG systems that treat pages or images in isolation, VISOR builds up a structured Evidence Space that accumulates and reasons across retrieval iterations. This helps overcome both sparse clues and search drift in long sequences, keeping the agentic AI system aligned to the original goal even as context grows.
The Core VISOR Loop: Retrieve → Reason → Crop/Zoom → Accumulate → Re-anchor → Answer
Each iteration of the VISOR loop performs the following steps:
- Retrieve candidate images or pages from the visual corpus
- Reason about what evidence has been gathered and what’s still missing
- Crop/Zoom into specific regions of interest using visual action evaluation
- Accumulate validated evidence into the structured Evidence Space
- Re-anchor to the original query intent via Intent Injection
- Answer when sufficient evidence is gathered, or loop again if not
This is a fundamentally different architecture from standard retrieval-augmented generation pipelines, which retrieve once and hand off to a language model. VISOR’s loop is closer to how a skilled analyst actually works through a complex document set.
The Two Big Bottlenecks VISOR Solves in Visual RAG
Agentic visual RAG has historically struggled with two major issues that have prevented enterprise adoption. Here is how VISOR addresses each one:
Bottleneck 1: Visual Evidence Sparsity
Relevant clues are often scattered across multiple pages or confined to tiny regions within a single image—like a specific cell in a dense table, or a footnote in a 40-page technical report. Standard visual RAG systems process each page in isolation and miss these distributed signals entirely.
VISOR solves this with a structured Evidence Space. Instead of processing each page in isolation, it explicitly accumulates query-relevant observations across iterations. It also uses a Visual Action Evaluation and Correction (VAEC) mechanism to assess “crop-and-zoom” actions, pruning noisy crops and only keeping validated evidence that actually moves the reasoning forward.
Bottleneck 2: Search Drift in Long-Horizon Tasks
Images consume thousands of tokens. In a multi-turn agentic search, the context window fills up fast, burying earlier evidence and causing the agent to “drift” from the original user intent. This is the same problem that causes AI hallucination and accuracy failures in long-running enterprise workflows.
VISOR fixes this with two mechanisms:
- Dynamic Trajectory: A sliding window that retains recent interactions while pinning the Evidence Space to the top of context, bounding growth without losing critical information.
- Intent Injection: Re-anchors the agent to the original query at every step, preventing goal drift even across dozens of retrieval iterations.
Why Visual RAG Matters for Enterprise AI in 2026
The shift from text-only RAG to visual RAG is one of the most important transitions happening in enterprise AI right now. As I covered in the breakdown of Meta’s Muse Spark multi-agent AI, the next generation of AI systems won’t just read text—they’ll reason across images, charts, diagrams, and mixed-media documents at scale.
The use cases where VISOR-style agentic visual RAG creates immediate enterprise value include:
- Visual inspection pipelines — manufacturing defect detection across thousands of images
- Complex claim triage — insurance and legal document review across multi-page visual evidence
- Field support systems — technicians cross-referencing multiple diagrams and manuals in real time
- Financial document analysis — earnings reports, charts, and tables requiring multi-step cross-referencing
- Medical imaging workflows — radiology reports requiring evidence accumulation across multiple scans
This connects directly to the broader agentic AI transformation happening across enterprise sectors—where the competitive advantage goes to organizations that can deploy AI systems capable of sustained, multi-step reasoning, not just fast single-pass lookups.
Performance Benchmarks: How VISOR Compares to Existing Visual RAG Systems
The benchmark results are highly promising. In tests spanning three major visual question-answering datasets—ViDoSeek, SlideVQA, and MMLongBench—VISOR outperforms existing agentic baselines by a noticeable margin.
Key Performance Findings
- State-of-the-art without fine-tuning: VISOR achieves top performance even without task-specific fine-tuning, suggesting strong generalization across visual domains.
- RL training amplifies gains: When trained end-to-end with reinforcement learning (using a Group Relative Policy Optimization pipeline), performance gains are even more significant.
- Consistent across dataset types: Strong results across slide decks (SlideVQA), video frames (ViDoSeek), and long-document benchmarks (MMLongBench) indicate the approach generalizes well.
For the full technical methodology and benchmark tables, see the VISOR paper on arXiv (April 2026).
The Cost-Performance Tradeoff: What Leaders Need to Understand
Where typical retrieval-augmented generation retrieves once then answers, VISOR’s dynamic trajectory and intent re-anchoring ensures the evidence you collect remains goal-focused across many steps. But this comes with real operational costs that leaders need to model before deployment.
The Upside: Much deeper multi-step reasoning over visual corpora. Lower time-to-resolution on complex visual tasks. Fewer human escalations in inspection and triage workflows. This is the kind of ROI that justifies the infrastructure investment—similar to the on-premises AI break-even math that has shifted dramatically in 2026.
The Downside: Higher costs per query. Because the agent is iteratively searching, cropping, and reasoning, you will see more retrieval queries, higher vector database usage, and increased token consumption compared to a standard RAG pipeline. For high-volume, low-complexity queries, standard RAG remains the right choice. For complex, high-value visual reasoning tasks, VISOR’s cost premium is justified by the accuracy and resolution speed gains.
The LangChain RAG documentation provides a useful framework for thinking about when to use agentic vs. standard RAG patterns in production systems.
Your Operator Action Plan: 3 Steps for Visual RAG Systems
If you are benchmarking or building visual RAG systems for enterprise deployment, here is what you need to do next:
-
Add iterative search scenarios to your visual RAG evaluations.
Stop testing your systems only on single-hop lookups. Build evaluations that require cross-referencing multiple images or zooming into specific regions. If your system can’t handle a 20-page technical diagram with the answer buried in a footnote, it’s not ready for enterprise deployment. This is the same rigor I recommend in evaluating AI systems for real-world performance. -
Track the right operational metrics.
Don’t just track accuracy. You need to monitor p95 latency, vector DB QPS (Queries Per Second), token consumption per query, and the net human-time saved to understand the true operational impact. Cost per correct resolution is the metric that matters for business cases. -
Prepare for operational cost tradeoffs at scale.
As retrieval volumes scale with agentic loops, your infrastructure costs will rise non-linearly. Model the ROI of higher accuracy vs. increased token and database costs for your specific use case before committing to production deployment. Build cost guardrails into your agentic loop architecture from day one.
Bottom-line: VISOR turns visual RAG into a true agentic workflow—expect higher query costs but significantly lower time-to-resolution for visual inspection, document intelligence, and multi-step reasoning pipelines. The organizations that build evaluation frameworks for this now will have a measurable head start.
Frequently Asked Questions About Visual RAG and VISOR
What is visual RAG (Retrieval-Augmented Generation)?
Visual RAG is a type of retrieval-augmented generation system that retrieves and reasons over images, charts, diagrams, and visual documents rather than (or in addition to) text. Standard RAG retrieves text chunks; visual RAG retrieves image regions or pages and uses multimodal AI models to reason over them.
How is VISOR different from standard visual RAG?
Standard visual RAG retrieves once and answers. VISOR uses an agentic loop that iteratively retrieves, reasons, crops into specific visual regions, accumulates evidence across multiple steps, and re-anchors to the original query intent at each step. This makes it far more capable on complex, multi-step visual reasoning tasks.
What are the main use cases for agentic visual RAG in enterprise?
The highest-value enterprise use cases include visual inspection pipelines, insurance and legal claim triage, field support with technical diagrams, financial document analysis, and medical imaging workflows where evidence must be gathered across multiple visual sources.
What are the cost implications of using VISOR vs. standard RAG?
VISOR uses more retrieval queries, more vector database operations, and more tokens per task than standard RAG. The cost premium is justified for complex, high-value visual reasoning tasks where accuracy and resolution speed matter. For simple, high-volume lookups, standard RAG remains more cost-efficient.
References
[1] VISOR: Agentic Visual Retrieval-Augmented Generation via Iterative Search and Over-horizon Reasoning — arXiv (April 2026) [2] What is Retrieval-Augmented Generation (RAG)? — Pinecone [3] Build a Retrieval Augmented Generation (RAG) App — LangChainAbout Jason Fleagle
Jason Fleagle is an AI and Growth Consultant and Head of AI for Netsync. He helps businesses leverage artificial intelligence, automation, and digital marketing to drive measurable ROI and scale operations. Follow the AI Pathfinder newsletter for weekly breakdowns of what’s actually moving in AI — and what it means for you.
If you want to build AI systems that actually drive revenue and operational leverage, let’s talk.


